- Classificazione dell’immagine (Image Classification): analisi del contenuto dell’immagine e attribuzione di un’etichetta di riconoscimento (es. cane, uomo, lampada, ecc.);
- Rilevamento degli oggetti (Object Detection): identificazione di tutte le entità presenti all'interno dell’immagine;
- Segmentazione dell’immagine (Image Segmentation): l’immagine viene suddivisa in sezione per essere analizzata nel dettaglio;
- Riconoscimento facciale (Face Recognition): task fondamentale per individuare dei volti di persone all’interno di un immagine;
- Riconoscimento di azioni (Action Recognition): identificazione delle entità all’interno dell’immagine e della loro relazione nello spazio e nel tempo per individuare azioni specifiche (es. un tennista che colpisce una palla)
- Rilevamento delle relazioni visive (Visual Relationship Detection): comprensione e interpretazione delle relazioni tra le entità presenti nell’immagine;
- Riconoscimento delle emozioni (Emotion Recognition): rilevamento del sentimenti dei volti presenti in un’immagine;
- Modifica dell’immagine (Image Editing): modifiche a un’immagine (es. oscuramento di dati sensibili).
Blog
23/03/2022
Computer Vision (AI) per il riconoscimento degli oggetti nelle immagini
23/03/2022
La visione umana è una capacità infinitamente bella e complessa.
Gli occhi si occupano di catturare la luce, i recettori accedono all'informazione e la corteccia cerebrale visiva le elabora.
Negli ultimi anni sono stati fatti molti passi avanti per estendere questa straordinaria capacità, non solo sugli esseri umani, ma anche sulle macchine.
Dal primo modello di fotocamera, in cui una piccola scatola contenente un pezzo di carta ricoperto di cloruro d’argento si scuriva con l’esposizione solare all’apertura dell’otturatore, fino alle più moderne macchine fotografiche e videocamere digitali dei nostri giorni.
Con questi apparecchi l’uomo è stato in grado di riprodurre il modo in cui l’occhio umano cattura luce e colori.
Ad oggi, grazie alla computer vision, stiamo affrontando un aspetto molto più complesso, ovvero quello di far capire e interpretare ai computer e alle macchine il contenuto di un'immagine nello stesso modo in cui lo interpreta il cervello umano.
Che Cos’è la Computer Vision
La computer vision o visione artificiale è una branca dell’intelligenza artificiale (AI) che studia e programma algoritmi e tecniche che consentono ai computer di replicare i processi e le funzioni dell’apparato visivo umano e di rilevare e interpretare informazioni importanti attraverso un'immagine digitale, un video o altri input visivi.
Con la computer vision, una macchina, non solo può riconoscere oggetti, animali o persone presenti all’interno di un'immagine digitale o di una sequenza video, ma può anche: estrapolare informazioni utili, interpretare i dati ricavati, elaborarli e intraprendere azioni o effettuare segnalazioni sulla base dei dati ottenuti.
Tramite tale processo il computer può capire i contenuti presenti dentro a un'immagine, ricostruire un contesto e attribuire un vero e proprio significato a ciò che rappresenta.
In sostanza possiamo dire che se l’AI è la disciplina che dona la capacità ai computer di pensare, la computer vision è quella che gli dona la capacità di vedere, capire e interpretare.
Per poter funzionare e riuscire a interpretare i contenuti presente all’interno di un immagine, i sistemi di computer vision devono essere prima "addestrati" attraverso un processo di machine learning e utilizzando una grande quantità di immagini catalogate, le quali saranno la base del dataset che permetterà all'algoritmo di riconoscere quelle successive in modo intelligente.
Il processo è simile al sistema di apprendimento umano, infatti i nostri occhi si sono allenati per anni e anni nel distinguere oggetti riuscendo infine a capire e interpretare.
Ovviamente un sistema di computer vision non dispone di retine, nervi ottici e di una corteccia visiva e per essere addestrato vengono utilizzate telecamere, algoritmi, dati e immagini opportunamente etichettate.
Come funziona la computer vision
La computer vision è basata sulle più avanzate tecniche di Machine Learning e su una grande mole di dati che consentono alla macchina di interpretare e capire un immagine con prestazioni paragonabili a quelle della vista umana.
Ma come fanno le macchine a riconoscere gli oggetti presenti in un immagine? Tutto il sistema è basato su 3 fasi fondamentali:
1. Acquisizione dell’immagine: le immagini o le sequenza video vengono acquisite dal computer, anche in tempo reale, tramite foto o tecnologia 3D, video, per finalità di analisi.
2. Elaborazionedell’immagine: attraverso dei modelli di deep learning la macchina riesce a elaborare l’immagine attraverso specifici task. Questi modelli vengono addestrati precedentemente tramite il caricamento di migliaia e migliaia di immagini etichettate e pre-identificate.
3. Interpretazione dell'immagine: infine la macchina identifica, comprende e classifica l’immagine elaborata e se necessario intraprende un'azione o una segnalazione. Gli algoritmi di Computer Vision possono effettuare operazioni più o meno avanzate su un immagine per interpretarla, a seconda delle tecniche impiegate e del tipo di task effettuato, tra cui:

Per effettuare tutti questi task e per comprendere un’immagine i sistemi di computer vision sfruttano il machine learning, ovvero un sistema di apprendimento automatico basato sull'intelligenza artificiale (AI) che utilizza i dati a sua disposizione per comprendere e migliorare le performance.
Il machine learning consente di addestrare i sistemi a capire il contesto di una foto sulla base di un set di dati e in questo modo il sistema può capire cosa rappresentano tutti i numeri che sta analizzando.
Infatti è fondamentale sapere che un computer non vede l’immagine così come la vediamo noi ma osserva un set di numeri da elaborare e interpretare a seconda di come sono organizzati.
La computer vision può allenarsi fino a diventare migliore e più abile della vista umana, infatti quando un’immagine è ambigua possiamo continuare ad allenare il sistema con altri tipi di immagini finché il computer avrà abbastanza dataset da riuscire a distinguerle perfettamente.
Le principali difficoltà che sta affrontando chi sviluppa questa tecnologia in questo momento sono:
- ottenere un dataset abbastanza ampio e completo per addestrare al meglio l’algoritmo.
- insegnare all’algoritmo a comprendere e interpretare anche immagini complesse con presenza di trasformazioni o deformazioni;
La Computer Vision sta affrontando sfide complesse anche se il sistema non è ancora perfetto e, come la vista umana, commette degli errori.
Deep Learning e Computer Vision
I risultati ottenuti e i progressi effettuati dalla computer vision sono dovuti all’intelligenza artificiale e alle tecniche più avanzate di machine learning, ovvero il deep learning.
Il deep learning è lo stadio successivo del machine learning e comprende tecniche di apprendimento automatico avanzate basate su reti neurali artificiali organizzate in livelli: ogni livello elabora i valori in favore di quello seguente, così da ottenere un'informazione completa.
Per ottenere le informazioni dalle immagini i sistemi di computer vision possono essere basati su tre tipologie di analisi da utilizzare singolarmente o in combinazione:
Hand Crafted Features: in questo caso l’algoritmo estrae quello che ritiene più rilevante all’interno di un immagine o sequenza video, come ad esempio la grandezza di un'entità, il colore, la forma e l’area che occupa.
Computer Vision Features: in questo caso l’algoritmo suddivide le immagini in parti più piccole per confrontarle con il dataset in modo da ottenere un’analisi più approfondita.
Data Driven Features: questa analisi più avanzata consente all’algoritmo di riconoscere e classificare le immagini senza la fase di estrazioni delle features che viene effettuata dalle reti neurali convoluzionali.
Rete neurale convoluzionale
Le Reti Neurali Convoluzionali in inglese Convolutional Neural Network (CNN) rappresentano uno degli algoritmi di Deep Learning tra i più utilizzati per i sistemi di computer vision e trovano applicazioni in: medicina, industria e automazione.
Il funzionamento alla base delle reti neurali consiste nel suddividere l’immagine in cluster di piccoli pixel chiamati filtri.
I gruppi di pixel ricavati vengono analizzati, elaborati e confrontati con altri pixel per trovare lo schema specifico che la rete neurale sta cercando in vari livelli.
Nel primo livello una CNN cerca di rilevare i modelli analizzando i bordi, gli spigoli e le curve presenti in un'immagine.
Man mano che la rete neurale esegue più convoluzioni può riuscire ad identificare entità specifiche come persone, oggetti e animali all’interno dell’immagine.
Per rendere precisa e accurata la previsione della CNN ogni iterazione del processo di analisi viene ripetuta utilizzando una funzione di errore che analizza il risultato fino a che il sistema di computer visione non è certo di aver compreso appieno il contenuto dell’immagine.
Applicazioni: le Immagini Diventano Parlanti
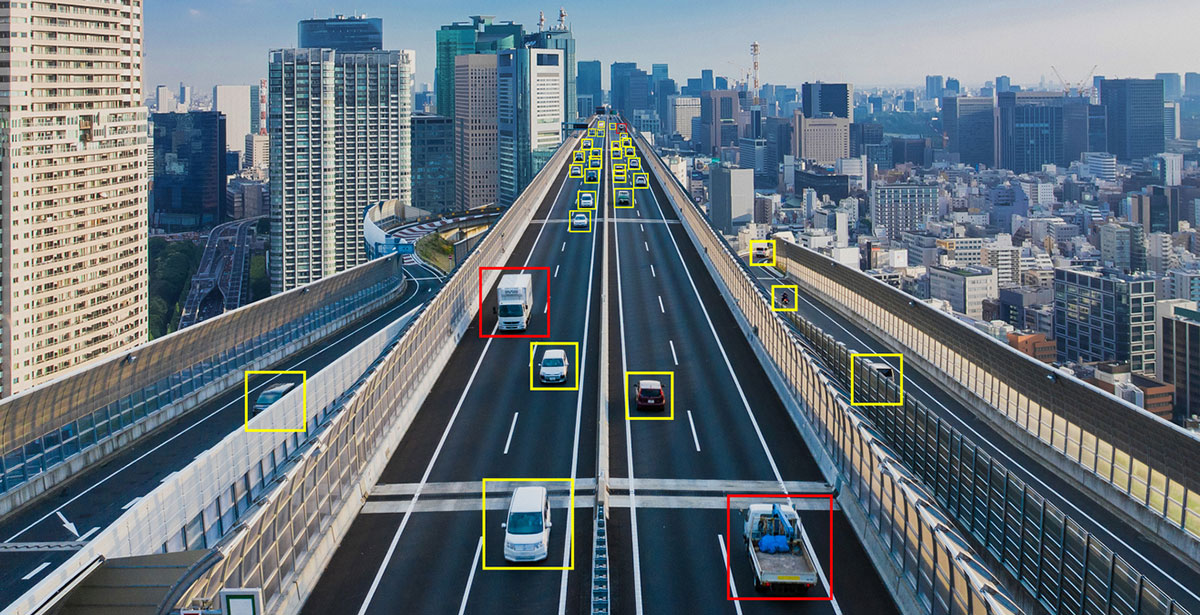
I sistemi di visione artificiali trovano applicazioni in moltissimi settori: dall’industria al retail, dalla telemedicina all'automotive, dal riconoscimento degli oggetti alla biometria, dalla smart surveillance (telecamere intelligenti per la videosorveglianza) al tracciamento di movimenti.
Ma i campi di applicazione delle Computer Vision sono innumerevoli e coinvolgono anche il settore manifatturiero, la manutenzione predittiva, il controllo dei processi, la realtà aumentata, il retail e il marketing.
Vediamo alcune applicazioni nel dettaglio.
Computer vision e medicina
La AI, il machine learning e la computer vision hanno portato dei grandissimi processi tecnologici in campo medico e scientifico supportando la ricerca e favorendo analisi e diagnosi avanzate e precise.
L’impiego del machine learning e dell’image recognition in campo medico hanno portato una riduzione del tempo per le diagnosi con risultati eccezionali in termini di accuratezza e precisione.
Un esempio delle potenzialità di queste tecnologie si può riscontrare nel loro utilizzo in campo oncologico dove le macchine vengono utilizzate con successo per diagnosticare in modo più veloce, accurato ed efficace i tumori.
Computer vision e automotive
La computer vision può essere lo strumento del futuro per combattere la piaga degli incidenti stradali. Sono circa 1,25 milioni le persone che ogni anno muoiono per colpa di un incidente e l’oms stima che il 20 % di essi è dovuto a stanchezza o distrazione. Un'applicazione della computer vision per la sicurezza stradale tra i più avanzati è sicuramente il progetto per la guida autonoma di waymo di Google.
Automobili equipaggiate con sensori e software che, grazie alla computer vision, riconoscono pedoni, animali, cantieri e ostacoli con una visione a 360° e un raggio d'azione di 300 metri.
Un altro progetto analogo è sicuramente quello della guida autonoma di Tesla che, come waymo basa la sua tecnologia su sistemi di Deep Neural Networks per guidare i veicoli in modo efficace.
Computer vision e anticontraffazione
L’anticontraffazione è sicuramente un tema spinoso e importante per conservare la qualità del marchio made in Italy.
La Visione artificiale è un valido aiuto in abbinamento ad altre tecnologie IoT, come ad esempio la tecnologia rfid.
I sistemi di visione artificiale possono rilevare un marchio o un logo per confrontarlo con l’originale e verificare così l’autenticità del prodotto in tempo reale.
Se sei interessato ai sistemi di anticontraffazione potrebbe interessarti anche:
Soluzioni Anticontraffazione grazie alla tecnologia RFID
Computer Vision e Smart Retail
Una delle applicazioni della visione artificiale che sta facendo più scalpore è sicuramente quella nell’ambito del retail, che ha dato luogo al termine Smart Retail. Un esempio è il negozio aperto da Amazon senza casse né cassiere.
Grazie al sistema di computer vision di Amazon go basato su un complesso numero di telecamere e software all’avanguardia, il cliente può entrare nel negozio, prelevare i prodotti che gli interessano e uscire senza fare la fila ne svuotare il carrello.
Il sistema di telecamere è in grado di rilevare quello che viene preso dagli scaffali in modo del tutto automatico e autonomo.
Computer vision e Retail Marketing
Grazie alla Computer Vision è possibile identificare le persone presenti all’interno di un luogo rilevando, il sesso, l’età, l’etnia, il colore degli occhi e perfino le emozioni che stanno provando mentre passeggiano per il nostro store.
Grazie alle analisi delle persone che hanno visitato un determinato negozio è possibile scoprire dati molto interessanti che consentano di effettuare promozioni mirate e incrementare le vendite.
Tali informazioni unite a un’analisi statistica permettono di attuare strategie di marketing e di vendita avanzate e personalizzate.
I principali progetti di Computer Vision

Ad oggi esistono molti tool e progetti che consentono il riconoscimento del contenuto di un'immagine basati sulla tecnologia di visione artificiale. I progetti più in vista sono:
Google Vision AI
Vision AI è un progetto Google, un utilissimo e avanzato tool con il quale è possibile rilevare e analizzare il contenuto di un'immagine anche in modo personalizzato secondo specifiche necessità. Questo strumento può essere utilizzato sia per la ricerca di prodotto che per l’ispezione della qualità.
Watson Visual Recognition
Watson Visual Recognition è la tecnologia di riconoscimento delle immagini di IBM. Il sistema tagga, classifica e cerca contenuti visivi in modo rapido e accurato utilizzando l'apprendimento automatico. Il servizio IBM WatsonTM Visual Recognition utilizza sofisticati algoritmi di deep learning per analizzare le immagini e individuare il contenuto presente all’interno.
Amazon Rekognition
Amazon Rekognition è il tool di riconoscimento delle immagini di amazon basato sulla visione artificiale. Con questo strumento è possibile rilevare volti, scene, oggetti e varie entità all’interno di un’immagine. Il sistema è basato sull’utilizzo di reti neurali profonde che consentono di rilevare e etichettare migliaia di entità all’interno delle immagini.
Clarifai
Clarifai è uno dei sistemi di computer vision più avanzati e accurati. Questa tecnologia consente di organizzare e taggare immagini e sequenze video sfruttando le potenzialità dell'intelligenza artificiale e il machine learning. Lo strumento mette a disposizione la potenzialità del face recognition al supporto dei settori retail, media e ospitalità.
Intelligenza Artificiale per il retail: Visual Merchandising 4.0
L’intelligenza artificiale applicata al campo del retail offre possibilità illimitate spostandosi dal piano virtuale a quello fisico.
Grazie ai sistemi di AI è possibile creare percorsi personalizzati e specifici all’interno dello store così da creare un percorso e un'esperienza di acquisto unica basata sugli interessi del cliente.
Grazie all'analisi dei Big Data rilevati con i sistemi di computer vision e deep learning è possibile posizionare i prodotti nel punto migliore per essere acquistati.
Questa tecnologia permette non solamente di vendere meglio i prodotti di punta ma anche di svuotare le rimanenze di magazzino al fine di aumentare il fatturato dell’azienda e limitare lo spreco.
