- Classification d’images (Image Classification) : analyse du contenu de l'image et attribution d'une étiquette de reconnaissance (par exemple, chien, homme, lampe, etc.) ;
- Détection d'objets (Object Detection) : identification de toutes les entités dans l'image ;
- Segmentation d'image (Image Segmentation) : l'image est divisée en sections pour une analyse détaillée ;
- Reconnaissance faciale (Face Recognition) : une tâche fondamentale pour identifier les visages des personnes dans une image ;
- Reconnaissance d’activités (Action Recognition) : identification d'entités dans l'image et de leur relation dans l'espace et le temps pour identifier des actions spécifiques (par exemple, un joueur de tennis frappant une balle).
- Détection des relations visuelles (Visual Relationship Detection) : comprendre et interpréter les relations entre les entités dans l'image ;
- Reconnaissance des émotions (Emotion Recognition) : détection des sentiments des visages dans une image ;
- Retouche numérique (Image Editing): modifications apportées à une image (par exemple, masquage de données sensibles)
Blog
23/03/2022
Vision par ordinateur (IA) pour la reconnaissance d'objets sur les images
23/03/2022
La vision humaine est une capacité infiniment belle et complexe.
Les yeux sont chargés de capter la lumière, les récepteurs accèdent aux informations et le cortex cérébral visuel les élabore.
Au cours des dernières années, de nombreuses mesures ont été prises pour étendre cette extraordinaire capacité, non seulement sur les humains, mais aussi sur les machines.
Depuis le premier modèle d'appareil photo, dans lequel une petite boîte contenant un morceau de papier recouvert de chlorure d'argent s'assombrissait à la lumière du soleil lorsque l'obturateur était ouvert, jusqu'aux appareils photo et caméscopes numériques les plus modernes d'aujourd'hui.
Grâce à ces dispositifs, l'homme a pu reproduire la manière dont l'œil humain capte la lumière et les couleurs.
Aujourd'hui, grâce à la vision par ordinateur, nous nous attaquons à un problème beaucoup plus complexe, c’est-à-dire faire en sorte que les ordinateurs et les machines comprennent et interprètent le contenu d'une image de la même manière que le cerveau humain.
Qu'est-ce que la vision par ordinateur ?
La vision par ordinateur ou vision artificielle est une branche de l'intelligence artificielle (IA) qui étudie et programme des algorithmes et des techniques permettant aux ordinateurs de reproduire les processus et les fonctions de l'appareil visuel humain et de détecter et d'interpréter des informations importantes à partir d'une image numérique, d'une vidéo ou de toute autre entrée visuelle.
Avec la vision par ordinateur, une machine peut non seulement reconnaître des objets, des animaux ou des personnes dans une image numérique ou une séquence vidéo, mais aussi : extrapoler des informations utiles, interpréter les données obtenues, les traiter et prendre des mesures ou émettre des avertissements sur la base des données obtenues.
Grâce à ce processus, l'ordinateur peut comprendre le contenu d'une image, reconstituer un contexte et attribuer une signification réelle à ce qu'elle représente.
En gros, on peut dire que si l'IA est la discipline qui donne aux ordinateurs la capacité de penser, la vision par ordinateur est celle qui leur donne la capacité de voir, de comprendre et d'interpréter.
Pour fonctionner et être en mesure d'interpréter le contenu d'une image, les systèmes de vision par ordinateur doivent d'abord être « formés » par un processus d'apprentissage automatique et en utilisant une grande quantité d'images cataloguées, qui constitueront la base de l'ensemble de données qui permettra à l'algorithme de reconnaître les images suivantes de manière intelligente.
Le processus est similaire au système d'apprentissage humain, puisque nos yeux ont été entraînés pendant des années pour distinguer les objets et finalement les comprendre et les interpréter.
Évidemment, un système de vision par ordinateur ne possède pas de rétines, de nerfs optiques et de cortex visuel et pour l'entraîner, on utilise des caméras, des algorithmes, des données et des images étiquetées de manière appropriée.
Comment fonctionne la vision par ordinateur ?
La vision par ordinateur repose sur les techniques d'apprentissage automatique les plus avancées et sur une grande quantité de données qui permettent à la machine d'interpréter et de comprendre une image avec des performances comparables à celles de la vue humaine.
Mais comment les machines reconnaissent-elles les objets dans une image ? L'ensemble du système repose sur 3 étapes fondamentales :
1. Acquisition d'images : des images ou des séquences vidéo sont acquises par ordinateur, même en temps réel, en utilisant des photos ou la technologie 3D, la vidéo, à des fins d'analyse.
2. Traitement de l'image : à l'aide de modèles d'apprentissage profond, la machine est capable de traiter l'image par le biais de tâches spécifiques. Ces modèles sont préalablement entraînés en chargeant des milliers et des milliers d'images étiquetées et pré-identifiées.
3. Interprétation de l'image : la machine identifie, comprend et classe ensuite l'image traitée et, si nécessaire, prend une mesure ou établit un rapport. Les algorithmes de vision par ordinateur peuvent effectuer des opérations plus ou moins avancées sur une image pour l'interpréter, selon les techniques utilisées et le type de tâche effectuée, notamment :

Pour effectuer toutes ces tâches et comprendre une image, les systèmes de vision par ordinateur utilisent un système d’apprentissage automatique basé sur l'intelligence artificielle (IA) qui utilise les données à sa disposition pour comprendre et améliorer ses performances.
L'apprentissage automatique permet d'entraîner les systèmes à comprendre le contexte d'une photo sur la base d'un ensemble de données, de cette façon, le système peut comprendre ce que représentent tous les chiffres qu'il analyse.
En effet, il est essentiel de savoir qu'un ordinateur ne voit pas l'image telle que nous la voyons mais regarde un ensemble de chiffres à traiter et à interpréter en fonction de leur organisation.
La vision par ordinateur peut s'entraîner pour devenir plus performante que la vision humaine. En fait, lorsqu'une image est ambiguë, nous pouvons continuer à entraîner le système avec d'autres types d'images jusqu'à ce que l'ordinateur dispose de suffisamment d'ensembles de données pour être capable de les distinguer parfaitement.
Les principales difficultés auxquelles sont confrontés ceux qui développent actuellement cette technologie sont les suivantes :
- obtenir un ensemble de données suffisamment grand et complet pour mieux entraîner l'algorithme,
- l'apprentissage de l'algorithme pour comprendre et interpréter des images même complexes avec la présence de transformations ou de déformations ;
La vision par ordinateur doit relever des défis complexes, même si le système n'est pas encore parfait et que, comme la vision humaine, elle commet des erreurs.
Apprentissage profond et vision par ordinateur
Les résultats obtenus et les progrès de la vision par ordinateur sont dus à l'intelligence artificielle et aux techniques les plus avancées de l'apprentissage automatique, c'est-à-dire l'apprentissage profond.
L'apprentissage profond est la prochaine étape de l'apprentissage automatique et comprend des techniques avancées d'apprentissage automatique basées sur des réseaux neuronaux artificiels organisés en couches : chaque couche traite les valeurs en faveur de la suivante, afin d'obtenir des informations complètes.
Pour obtenir des informations à partir des images, les systèmes de vision par ordinateur peuvent se baser sur trois types d'analyse à utiliser individuellement ou en combinaison :
Hand Crafted Features (extraction des caractéristiques) : dans ce cas, l'algorithme extrait ce qu'il considère comme le plus pertinent dans une image ou une séquence vidéo, comme la taille d'une entité, sa couleur, sa forme et la zone qu'elle occupe.
Computer Vision Features (caractéristiques de vision par ordinateur) : dans ce cas, l'algorithme subdivise les images en parties plus petites pour les comparer avec l'ensemble de données afin d'obtenir une analyse plus approfondie.
Data Driven Features (caractéristiques axées sur les données) : cette analyse plus avancée permet à l'algorithme de reconnaître et de classer les images sans la phase d'extraction des caractéristiques qui est effectuée par les réseaux neuronaux convolutifs.
Réseau neuronal convolutif
Les réseaux neuronaux convolutifs Convolutional Neural Network (CNN) en anglais sont l’un des algorithmes d'apprentissage profond les plus utilisés pour les systèmes de vision par ordinateur et trouvent des applications dans la médecine, l'industrie et l'automatisation.
L'opération de base des réseaux neuronaux consiste à diviser l'image en groupes de petits pixels appelés filtres.
Les groupes de pixels obtenus sont analysés, traités et comparés à d'autres pixels pour trouver le motif spécifique que le réseau neuronal recherche à différents niveaux.
Au premier niveau, un CNN tente de détecter des motifs en analysant les bords, les coins et les courbes d'une image.
Au fur et à mesure que le réseau neuronal effectue davantage de convolutions, il peut être en mesure d'identifier des entités spécifiques telles que des personnes, des objets et des animaux dans l'image.
Pour que la prédiction du CNN soit précise et exacte, chaque itération du processus d'analyse est répétée à l'aide d'une fonction d'erreur qui analyse le résultat jusqu'à ce que le système de vision par ordinateur soit certain d'avoir parfaitement compris le contenu de l'image.
Applications : les images deviennent parlantes
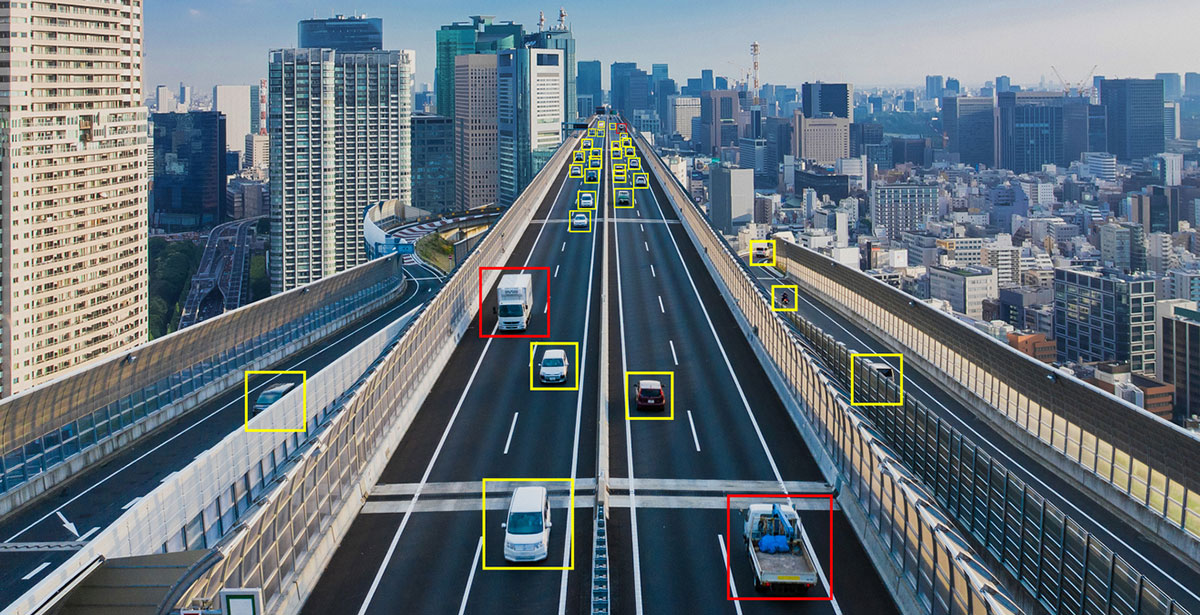
Les systèmes de vision artificielle trouvent leur place dans un large éventail de secteurs : de l'industrie au commerce de détail, de la télémédecine à l'automobile, de la reconnaissance d'objets à la biométrie, de la surveillance intelligente (caméras intelligentes pour la vidéosurveillance) au suivi des mouvements.
Les domaines d'application de la vision par ordinateur sont extrêmement nombreux et concernent également le secteur manufacturier, la maintenance prédictive, le contrôle des processus, la réalité augmentée, la vente au détail et le marketing.
Examinons en détail certaines de ces applications.
La vision par ordinateur et la médecine
L'IA, l'apprentissage automatique et la vision par ordinateur ont apporté des avancées technologiques majeures dans les domaines médical et scientifique, soutenant la recherche et facilitant les analyses et les diagnostics avancés et précis.
L'utilisation de l'apprentissage automatique et de la reconnaissance d'images dans le domaine médical a permis de réduire le délai de diagnostic avec des résultats exceptionnels en termes d'exactitude et de précision.
Un exemple du potentiel de ces technologies peut être trouvé dans leur utilisation dans le domaine de l'oncologie, où les machines sont utilisées avec succès pour diagnostiquer les tumeurs plus rapidement, plus précisément et plus efficacement.
La vision par ordinateur et le secteur automobile
La vision par ordinateur pourrait être l'outil du futur pour lutter contre le fléau des accidents de la route. Environ 1,25 million de personnes meurent chaque année dans des accidents et l'OMS estime que 20 % de ces décès sont dus à la fatigue ou à la distraction. L'une des applications les plus avancées de la vision par ordinateur pour la sécurité routière est certainement le projet de conduite autonome waymo de Google.
Des voitures équipées de capteurs et de logiciels qui, grâce à la vision par ordinateur, reconnaissent les piétons, les animaux, les chantiers et les obstacles avec une vue à 360° et une portée de 300 mètres.
Un autre projet similaire est certainement le projet de conduite autonome de Tesla qui, comme waymo, base sa technologie sur des systèmes de réseaux neuronaux profonds pour guider efficacement les véhicules.
La vision par ordinateur et la lutte contre la contrefaçon
La lutte contre la contrefaçon est sans aucun doute une question épineuse et importante pour préserver la qualité de la marque made in Italy.
La vision artificielle est une aide valable en combinaison avec d'autres technologies IoT, comme la technologie rfid.
Les systèmes de vision artificielle peuvent détecter une marque ou un logo pour le comparer à l'original et ainsi vérifier l'authenticité du produit en temps réel.
Si vous êtes intéressé par les systèmes de lutte contre la contrefaçon, vous pourriez également être intéressé par :
Solutions anti-contrefaçon grâce à la technologie RFID
La vision par ordinateur et le commerce intelligent
L'une des applications de la vision par ordinateur qui suscite le plus d'émoi est certainement le domaine de la vente au détail, qui a donné naissance au terme Smart Retail. Un exemple est le magasin ouvert par Amazon sans caissiers ni caisses.
Grâce au système de vision par ordinateur d'Amazon go, qui repose sur un nombre complexe de caméras et de logiciels de pointe, les clients peuvent entrer dans le magasin, prendre les produits qui les intéressent et repartir sans faire la queue ni vider leur panier.
Le système de caméra est capable de détecter ce qui est pris dans les rayons de manière entièrement automatique et autonome.
La vision par ordinateur et le retail marketing
Grâce à la vision par ordinateur, il est possible d'identifier les personnes présentes dans un lieu en détectant leur sexe, leur âge, leur origine ethnique, la couleur de leurs yeux et même les émotions qu'elles ressentent lorsqu'elles traversent notre magasin.
En analysant les personnes qui ont visité un magasin particulier, il est possible de découvrir des données très intéressantes qui peuvent être utilisées pour réaliser des promotions ciblées et augmenter les ventes.
Ces informations, combinées à des analyses statistiques, permettent de mettre en œuvre des stratégies de marketing et de vente avancées et personnalisées.
Les principaux projets de la vision par ordinateur

À ce jour, il existe de nombreux outils et projets qui permettent de reconnaître le contenu d'une image en se basant sur la technologie de la vision par ordinateur. Les projets les plus importants sont les suivants :
Google Vision AI
Vision AI est un projet de Google, un outil très utile et avancé avec lequel il est possible de détecter et d'analyser le contenu d'une image, également de manière personnalisée en fonction de besoins spécifiques. Cet outil peut être utilisé tant pour la recherche de produits que pour l'inspection de la qualité.
Reconnaissance visuelle de Watson
Watson Visual Recognition (Reconnaissance visuelle de Watson) est la technologie de reconnaissance d'images d'IBM. Le système étiquette, classe et recherche le contenu visuel rapidement et avec précision grâce à l'apprentissage automatique. Le service de reconnaissance visuelle d’IBM WatsonTM utilise des algorithmes sophistiqués d'apprentissage profond pour analyser les images et en identifier le contenu.
Amazon Rekognition
Amazon Rekognition est l'outil de reconnaissance d'image basé sur la vision artificielle d'Amazon. Cet instrument permet de détecter des visages, des scènes, des objets et diverses entités dans une image. Le système repose sur l'utilisation de réseaux neuronaux profonds capables de détecter et d'étiqueter des milliers d'entités dans les images. [lien : Amazon Rekognition -> ]
Clarifai
Clarifai est l'un des systèmes de vision par ordinateur les plus avancés et les plus précis. Cette technologie permet d'organiser et de baliser des images et des séquences vidéo en utilisant la puissance de l'intelligence artificielle et de l'apprentissage automatique. Cet instrument met la puissance de la reconnaissance faciale au service des secteurs du commerce de détail, des médias et de l'hôtellerie.
L’intelligence artificielle pour le commerce de détail : Visual Merchandising 4.0
L'intelligence artificielle appliquée au commerce de détail offre des possibilités illimitées en passant du plan virtuel au plan physique.
Grâce aux systèmes d'IA, il est possible de créer des parcours personnalisés et spécifiques au sein du magasin afin de créer un parcours et une expérience d'achat uniques en fonction des intérêts du client.
Grâce à l'analyse des Big Data collectées par les systèmes de vision par ordinateur et d'apprentissage profond, il est possible de positionner les produits au meilleur point d'achat possible.
Cette technologie permet non seulement de mieux vendre les meilleurs produits, mais aussi de vider les stocks afin d'augmenter le chiffre d'affaires de l'entreprise et de limiter le gaspillage.
