- Image classification: analysis of the image content and attribution of an identification label (e.g. dog, man, lamp, etc.);
- Object Detection: identification of all entities in the image;
- Image Segmentation: the image is divided into segments for detailed analysis;
- Face Recognition: an essential task for identifying people’s faces in an image;
- Action Recognition: identification of the entities in the image and their relationship in space and time to identify specific actions (e.g. a tennis player hitting a ball)
- Visual Relationship Detection: the understanding and interpretation of the relationships between the entities in the image;
- Emotion Recognition: detection of the emotions of faces in an image;
- Image Editing: making changes to an image (e.g. obscuring sensitive data).
Blog
23/03/2022
Computer Vision (AI) recognising objects in images
23/03/2022
Human sight is an incredibly beautiful and complex ability.
Our eyes capture the light, receptors access the information and the visual cortex interprets it.
In recent years, significant progress has been made in advancing this amazing ability not just in human beings, but also on machines.
From the first camera model, in which a small box containing a piece of paper coated in silver chloride was darkened through exposure to the sun when the shutter was opened, to the latest digital and video cameras available today.
These devices have given us the ability to reproduce the way in which the human eye captures light and colours.
Now, however, thanks to computer vision, we are taking on a much more complex aspect, i.e. making computers and machines understand and interpret the content of an image in the same way that the human brain interprets it.
What is computer vision?
Computer vision or artificial vision is a branch of artificial intelligence (AI) that studies and programs algorithms and techniques that allow computers to replicate the processes and functions of the human visual system and to detect and interpret key information through a digital image, video or other visual inputs.
With computer vision, a machine can not only recognise objects, animals or people in a digital image or video sequence, but it can also:
extrapolate useful information, interpret the data obtained, process it and take actions or send alerts based on the data obtained.
Through this process, the computer can understand the contents in an image, reconstruct a context and attribute a true meaning to what it represents.
In short, we could say that if AI is the discipline that gives computers the ability to think, computer vision is the one that gives them the ability to see, understand and interpret.
In order to operate and interpret the contents of an image, the computer vision systems must first be “trained” through a machine learning process, using a large number of catalogued images which will form the basis of the dataset that allow the algorithm to recognise subsequent ones in an intelligent manner.
The process is similar to the way humans learn; our eyes are, in fact, trained for many years to distinguish objects before finally managing to understand and interpret them.
Obviously, a computer vision system does not have retinas, optic nerves and a visual cortex so, appropriately labelled cameras, algorithms, data and images are used to train them.
How does computer vision work?
Computer vision is based on the most advanced Machine Learning techniques and on a huge amount of data that allow the machine to interpret and understand an image with a performance on a level with human sight.
But how do machines recognise the objects in an image? The entire system is based on three key phases:
1. Image acquisition: images or video sequences are acquired by the computer, including in real time, using photos or 3D technology, video, for analysis purposes.
2. Image processing: through in-depth learning models, the machine is able to process the image through specific tasks. These models are trained in advance by uploading thousands and thousands of tagged and pre-identified images.
3. Image interpretation: lastly, the machine identifies, understands and classifies the processed image and, if necessary, performs an action or sends an alert. Computer vision algorithms can perform more or less advanced operations on an image to in order to interpret it, depending on the techniques used and the type of task performed, including:

To carry out all these tasks and understand an image, computer vision systems use machine learning, which is a machine learning system based on artificial intelligence (AI) that uses the data at its disposal to understand and improve performance.
Machine learning allows you to train systems to understand the context of a photo based on a set of data and so, the system can understand the meaning of all the numbers it is analysing.
It is, in fact, important to know that a computer does not see the image as we see it but observes a set of numbers to be processed and interpreted according to how they are organised.
Computer vision can be trained until it improves and becomes more skilled than human sight. Indeed, when an image is ambiguous, we can continue to train the system with other types of images until the computer has enough datasets to be able to distinguish them perfectly.
The main difficulties that are being tackled by developers of this technology are:
- obtaining a sufficiently large and complete dataset to better train the algorithm.
- teaching the algorithm to understand and interpret complex images that also include transformations or deformations;
Computer vision is facing complex challenges even if the system is not yet perfect and, like human sight, it makes mistakes.
Deep Learning and Computer Vision
The results obtained and the progress being made by computer vision are due to artificial intelligence and the most advanced techniques of machine learning, i.e. deep learning.
Deep learning is the next stage in machine learning and includes advanced automatic learning base on artificial neural networks organised in levels: each level processes the data for the next level in order to obtain a complete set of information.
To obtain information from the images, the computer vision systems can be based on three types of analysis for use individually or in combinations:
Hand Crafted Features: in this case, the algorithm extracts what it deems most relevant within an image or video sequence, such as the size of an entity, colour, shape and area it occupies.
Computer Vision Features: in this case, the algorithm splits the images into smaller parts to compare them with the dataset in order to obtain a more in-depth analysis.
Data Driven Features: this more advanced analysis allows the algorithm to recognise and classify images without the feature extraction phase that is carried out by convolutional neural networks.
Convolutional neural network
Convolutional Neural Networks (CNN) are one of the most commonly used Deep Learning algorithms for computer vision systems and are found in: medicine, industry and automation.
Neural networks work by dividing the image into clusters of small pixels called filters.
The groups of pixels thus created are analysed, processed and compared with other pixels to find the specific pattern that the neural network is looking for on various levels.
On the first level, a CNN tries to detect pattens by analysing the edges, corners and curves in an image.
As the neural network performs more convolutions, it may be able to identify specific entities such as people, objects and animals in the image.
To make the CNN prediction precise and accurate, each iteration of the analysis process is repeated using an error function that analyses the result until the computer vision system is certain that it has fully understood the content of the image.
Applications: images that can talk
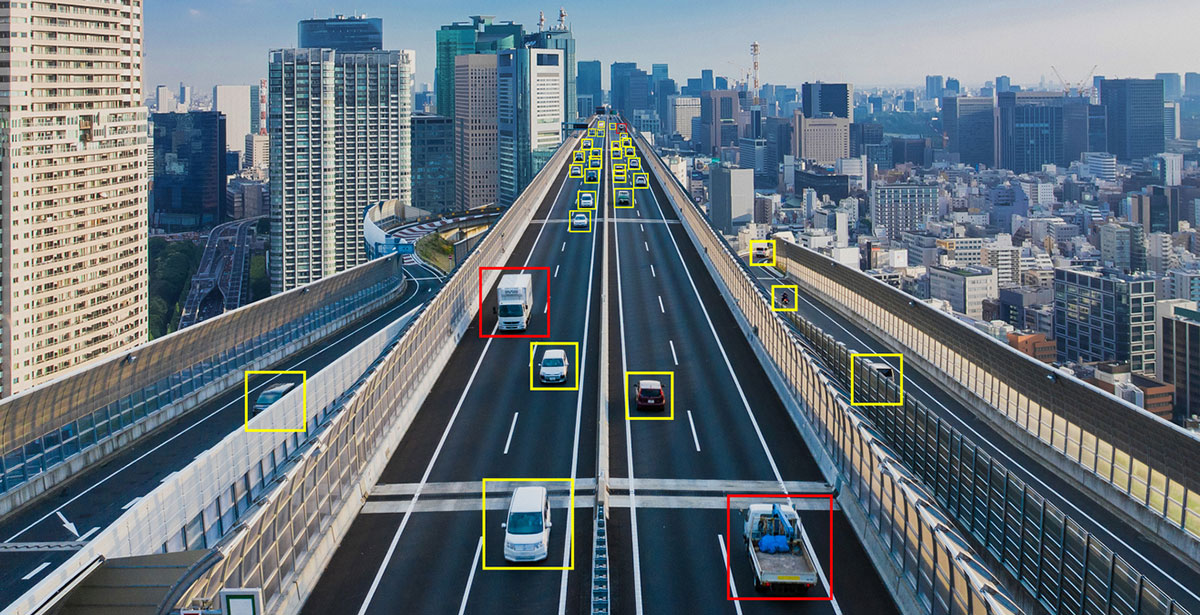
Artificial vision systems are used in many sectors: from industry to retail, telehealth to automotive, object recognition to biometrics, and from smart surveillance (intelligent cameras for video surveillance) to movement tracking.
But there are innumerable fields of use for computer vision which also involve the manufacturing sector, predictive maintenance, process control, augmented reality, retail and marketing.
Let’s take a closer look at some of the uses.
Computer vision and medicine
AI, machine learning and computer vision have led to significant technological processes to the medical and scientific fields, supporting research and contributing to advanced and precise analyses and diagnoses.
The use of machine learning and image recognition in the medical field has led to a reduction in diagnoses times with exceptional results in terms of accuracy and precision.
An example of the potential of these technologies can be found in their use in the oncology field where machines are successfully deployed to diagnose tumours more quickly, accurately and effectively.
Computer vision and vehicles
Computer vision may well be the tool of the future to combat the dire problem of road accidents. About 1.25 million people die each year in an accident and the WHO estimates that 20% of them are due to fatigue or distraction. One of the most advanced applications of computer vision for road safety is, without a doubt, Google's waymo driverless car project.
Cars fitted with sensors and software that, thanks to computer vision, can recognise pedestrians, animals, construction sites and obstacles with a 360° view and a range of 300 metres.
Another similar project is certainly Tesla's self-driving car which, like waymo, bases its technology on Deep Neural Networks systems to drive vehicles effectively.
Computer vision and combating counterfeiting
Combating counterfeiting is a obviously a thorny and pressing issue for protecting the quality of the Made in Italy brand.
Artificial vision is a valuable aid in combination with other IoT technologies, such as rfid technology.
Machine vision systems can detect a brand or logo to compare it with the original and thus verify the authenticity of the product in real time.
If you are interested in anti-counterfeiting systems, you may also be interested in:
Anti-counterfeiting solutions using RFID technology
Computer Vision and Smart Retail
One of the uses of computer vision that is causing the biggest stir is the one in the retail world, known as Smart Retail. An example is Amazon’s open store with no cash desks or cashiers.
Thanks to the Amazon go computer vision system based on a complex number of cameras and cutting-edge software, customers can enter the store, pick up the products they are interested in and leave without queuing or emptying their shopping trolley.
The camera system is able to detect what is taken off the shelves automatically and independently.
Computer vision and Retail Marketing
Thanks to Computer Vision, it is possible to identify people in a place by detecting their gender, age, ethnicity, eye colour and even the emotions they are experiencing while walking through the store.
By analysing the people who have visited a particular store, it is possible to uncover highly interesting data for use in targeted promotions and increasing sales.
This information combined with statistical analysis allows you to implement advanced and personalized marketing and sales strategies.
The main computer vision projects

There are currently a whole host of tools and projects that allow image content recognition based on computer vision technology. The most notable projects are:
Google Vision AI
Vision AI is a Google project, a very useful and advanced tool which makes it possible to detect and analyse the content of an image even in a personalized way according to specific needs. This tool can be used for both product research and quality inspection.
Watson Visual Recognition
Watson Visual Recognition is IBM's image recognition technology. The system tags, classifies and searches for visual content quickly and accurately using machine learning. The IBM WatsonTM Visual Recognition service uses sophisticated deep learning algorithms to analyse images and identify the content.
Amazon Rekognition
Amazon Rekognition is Amazon's image recognition tool based on artificial vision. With this tool, it is possible to detect faces, scenes, objects and various entities in an image. The system is based on the use of deep neural networks that allow the detection and labelling of thousands of entities in images.
Clarifai
Clarifai is one of the most advanced and accurate computer visions systems. This technology allows you to organise and tag images and video sequences by exploiting the potential of artificial intelligence and machine learning. The tool makes the potential of face recognition available to support the retail, media and hospitality sectors.
Artificial Intelligence for retail: Visual Merchandising 4.0
Artificial intelligence applied to the retail field offers unlimited possibilities by moving from the virtual to the physical arena.
Thanks to AI systems, it is possible to create personalised and specific paths within the store aimed at creating a unique shopping path and experience based on the customer's interests.
Thanks to the analysis of Big Data detected with computer vision and deep learning systems, it is possible to position products in the best place to be purchased.
This technology allows you not only to improve the sale of leading products but also to eliminate stock and thus increase the company's turnover and limit waste.
